
タイトル : 駅別乗降人員の推移 推移の分析 コロナの影響
更新日 : 2024-04-30
カテゴリ : プログラミング
乗降人員の推移をPLOTしてみましょう
コロナの影響で2020年度にかなり減少していますね。
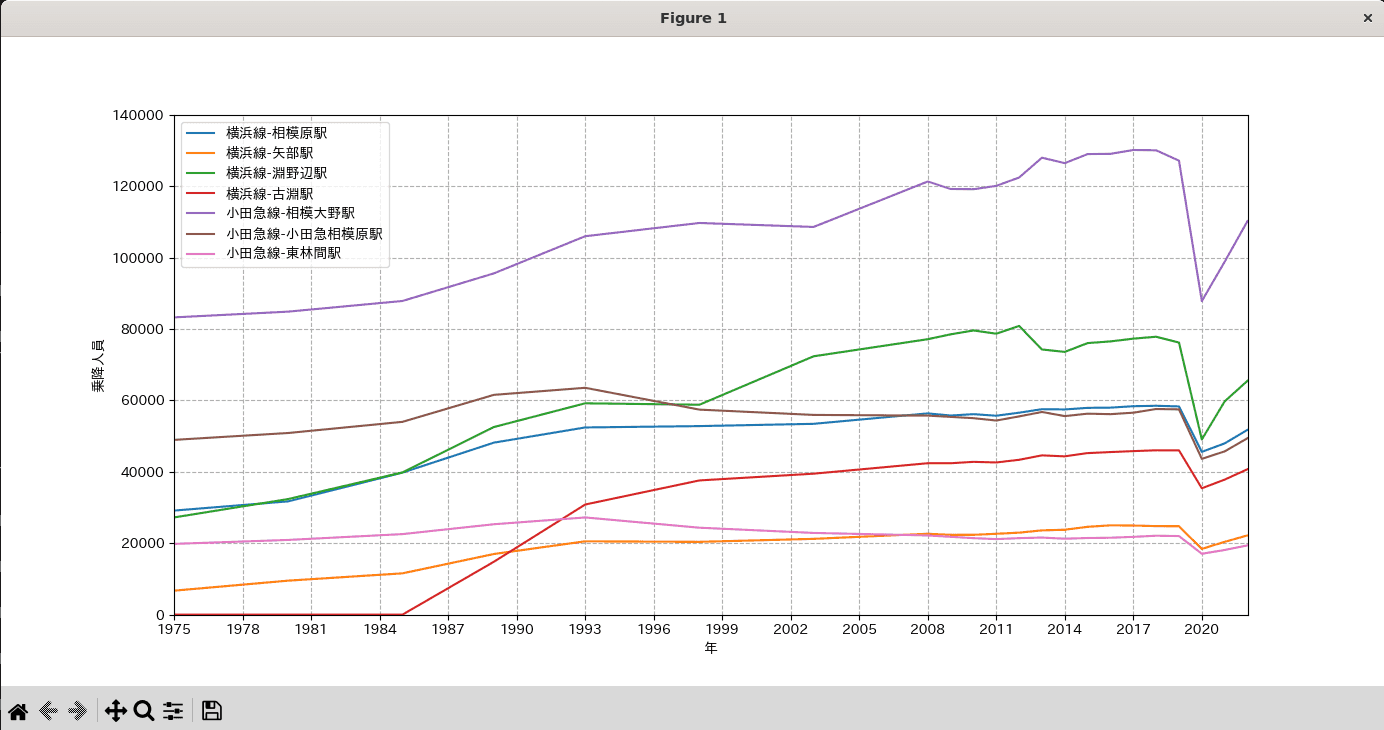
- 南側の東林間、小田急相模原のピークは1993年だけど、北側は増加傾向がありそう
コロナの影響
コロナ前の2018年度を1にしてPLOTしてみます
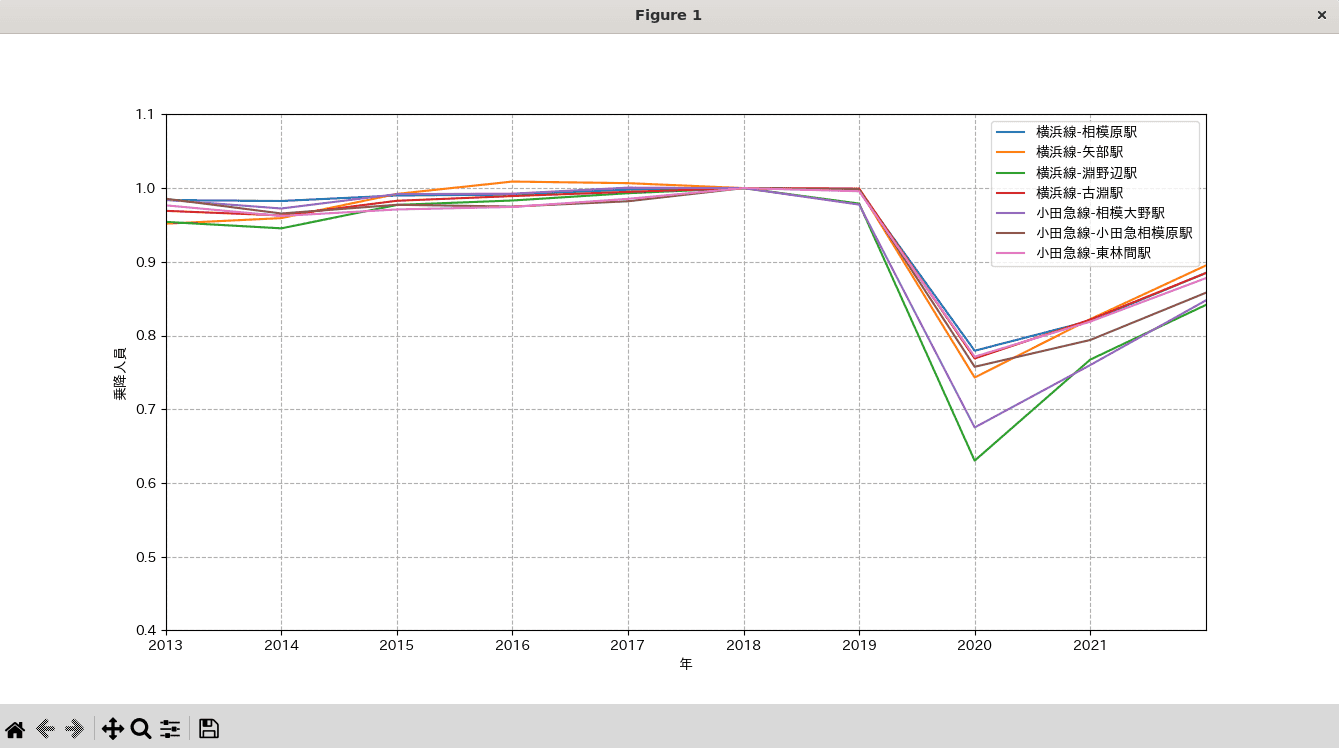
-
淵野辺、相模大野とそれ以外で傾向が異なっている。コロナの影響を受けやすい移動を行う人の割合が高いと思われる
-
2019年度の数値が淵野辺、相模大野で下がっているのは、コロナの影響を受けやすかったせいで減少傾向にあったわけではないか。全駅でほぼ緩やかな増加傾向中だったか
-
2020年度から、2021年度、2022年度とほぼ線形で回復している。線形だとすると今年度末にはコロナ前の水準に戻っているのかな~
リモートワーク等の影響があってコロナ前の水準に乗降人員が戻ることがないイメージだったけど...リモートワーク等の影響が大きくないってことなのかな~全国的な傾向? 相模原市の傾向?
2020年度、2021年度、2022年度での相関係数は以下です。かなり線形だけど、なぜほぼ線形なんだろうか
駅名 相関係数 小田急線-相模大野駅 0.999947 横浜線-矢部駅 0.999700 横浜線-古淵駅 0.998609 小田急線-東林間駅 0.998112 横浜線-相模原駅 0.991244 小田急線-小田急相模原駅 0.987547 横浜線-淵野辺駅 0.985522 相関係数は numpy の corrcoef(x, y) で出しています
最初のチャートのPythonスクリプト
import csv
from matplotlib import pyplot
import japanize_matplotlib
import numpy as np
# データ読み込み
filename = "shtrain_utf8.csv"
with open(filename, encoding="utf8", newline="") as f:
csvreader = csv.DictReader(f)
datas = [row for row in csvreader]
# x軸(年)
years = [int(key.replace("年度", "")) for key in datas[0] if key.find("年度") > -1]
years = sorted(years)
# plot
for data in datas:
if data["駅名"] in [
"相模原駅",
"矢部駅",
"淵野辺駅",
"古淵駅",
"相模大野駅",
"小田急相模原駅",
"東林間駅",
]:
y_data = []
for y in years:
v = data[f"{y}年度"]
if v:
y_data.append(int(v))
else:
y_data.append(0)
pyplot.plot(years, y_data, label=f"{data['路線名']}-{data['駅名']}")
pyplot.legend()
pyplot.xlabel("年")
pyplot.ylabel("乗降人員")
pyplot.xticks(np.arange(years[0], years[-1], step=3))
pyplot.xlim(years[0], years[-1])
pyplot.ylim(0, 140000)
pyplot.grid(linestyle="--")
pyplot.show()